AWS S3 is one of the first services that Amazon introduced and it’s used for storing data (objects) in the cloud. By an API you can performance CRUD operations in S3. This service is billed for the storage you really use so you don’t have to worry about capacity estimated and so on.
S3 is used by other AWS services like Amazon Kinesis or Amazon EBS.
How can I do with AWS S3?
The main use case could be storing files to serve by Internet like images, videos, content files or software packages for distribution.
There are other uses cases:
- Hosting for websites
- Hosting for serve mobile applications files (apk / ipa)
- Backup for on-premise or cloud data
Theoretically, the amount of data that you can store in S3 it’s unlimited.
This is awesome but… where (in the world) are my files or data?
Cloud means global but you decide where you want to create your bucket and for consequence, where your files and data are going to be stored. So you have the control about where your data is.
If you don’t have any legal restrictions to store your data, when you’re creating the bucket, the best decission is to choose an AWS Region close to your customer in order to minimize latency. If you have legal requirements, you can choose an AWS Region that satisfies those requirements. Or if you are going to use S3 for Disaster Recovery, a good decission is to choose an AWS Region far away from your main location.
What is that called “Object Storage”?
Traditionally we work with two kinds of storage:
- block storage: operates at lower level (raw storage) and manages data as a cluster of blocks.
- file storage: operates on top of block storage (operating system level) and manage data as files or folders.
These two kind of storage are associated (coupled) with the operating system and the machine/server managing the storage.
Object Storage is totally decoupled of the server and its operating system because it’s used by Internet using HTTP calls. An Object is identified by a unique key (like a filename) and it’s associated to a kind of data container called “bucket”. It’s size can be between 0 and 5TB.
An Object is formed by:
- data: stream of bytes
- metadata: set of key/value pairs that describe the object. There are two kinds of metadata:
- system metadata: keys are created by Amazon and the user only can assign the values
- user metadata (tags): it's optional and it's managed by the user, keys and values.
Every object is identified by a key, as a filename was. The key length can be up to 1024 bytes and admits almost everything: slashes, backslahes, dots…
What is a “Bucket”?
A Bucket is a cluster of Objects without hierarchy, organized in a flat structure (“sub-buckets don’t exist)”. Each bucket can hold an unlimited number of objects so there is an unlimited storage (you only pay for the storage you use)
It’s important to know that the bucket names are global in AWS. It means that there can’t exist two bucket with the same name in all AWS accounts.
For this reason it’s important to define good bucket names for your project using, for instance, rules that can identify and associate easily that bucket with your project.
Inside a bucket, there can’t have two objects with the same key but it can between several buckets because the object key identifies to the object in the bucket that it belongs.
By default, you can create 100 buckets per account.
How can read to my data through Internet?
As I said before, the access to S3 objects are by HTTP calls so you can download an object simply by writing an URL in your browser. By this way, you can consume your objects from any device or operating system.
These URLs have the following structure:
http://
.s3.amazonaws.com/
Examples:
- http://mybucket.s3.amazonaws.com/myobject.pdf
- http://mycompany.myproject.mybucket.s3.amazonaws.com/myobject.pdf
- http://mycompany.myproject.mybucket.s3.amazonaws.com/myprojectroot/mygroup/myobject.pdf
As you can see, bucket names can contains numbers, hyphens and periods in order to a better identification.
In the last example, the key of the object (its “name”) is myprojectroot/mygroup/myobject.pdf. This is important because as I mentioned before, there is no hierarchy inside a bucket.
And…How can manage completely my data through Internet? By an API?
Yes, the answer is that there is a REST API and you can use both http and https to execute operations.
The main operations you can execute are:
- Create a bucket
- Delete a bucket
- Create an object
- Read an object
- Delete an object
For more detail, you can access to the official documentation
Show me the service!
Ok, let’s move to some practical.
Using S3 service isn’t hard if you know what a bucket and an object are. In this example, we are going to use the service by the web console. In next posts we’ll show how to use the service by the AWS CLI and the AWS SDK.
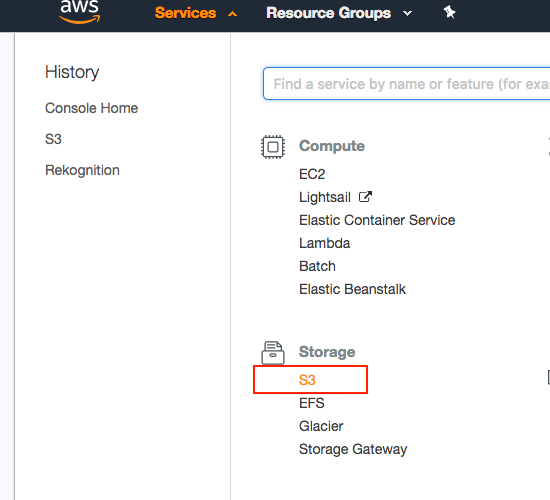
The first step is enter to your account and accessing to S3 service
Creating the bucket
As I said in previous section, every object is contained in a bucket, so we have to create the bucket before uploading objects. To create a new one you have to click in “Create Bucket” button.
It’s important to highlight (again) the fact that a bucket name is global in AWS so you have be careful with your buckets names and set certain rules to create a good bucket names.
In this case, I’m going to use “jaruiz.io.s3examples” as my bucket name:
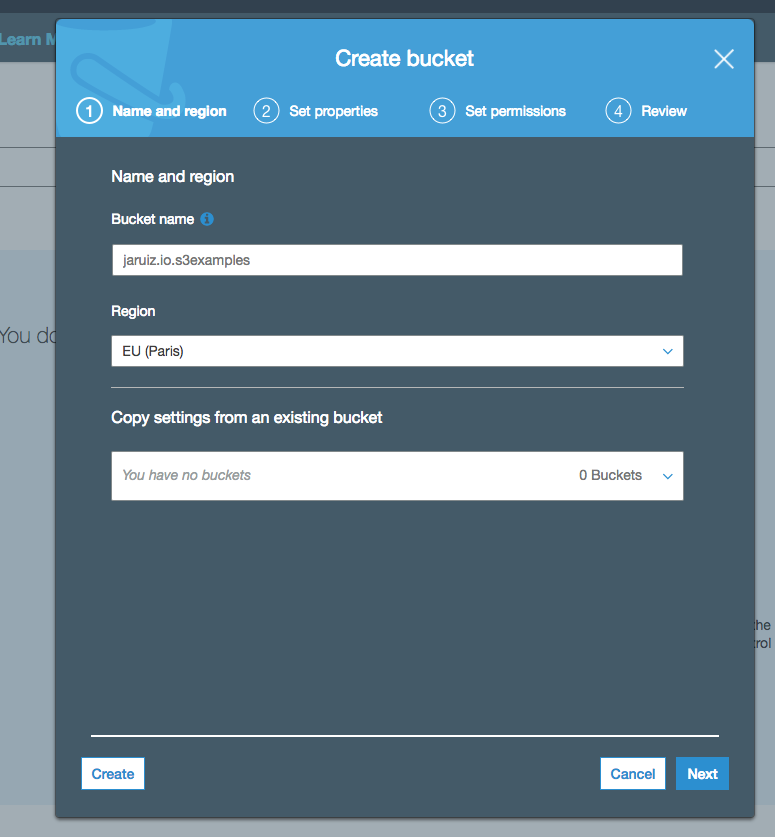
When your are creating a bucket, you have to choose where you want to store your data so you must enter the AWS Region in where your bucket will be created. In this case, I’m selecting Paris because it’s the closest one to “my customers”.
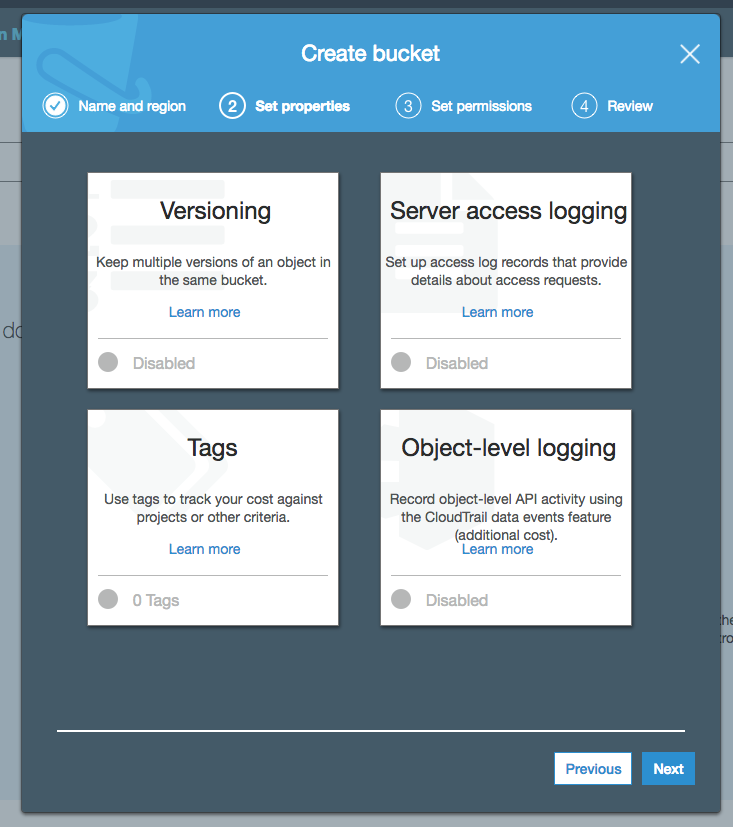
The next step is setting the bucket properties. We’ll see in next posts advanced features of AWS S3 using this properties. In this example, we select the properties by default.
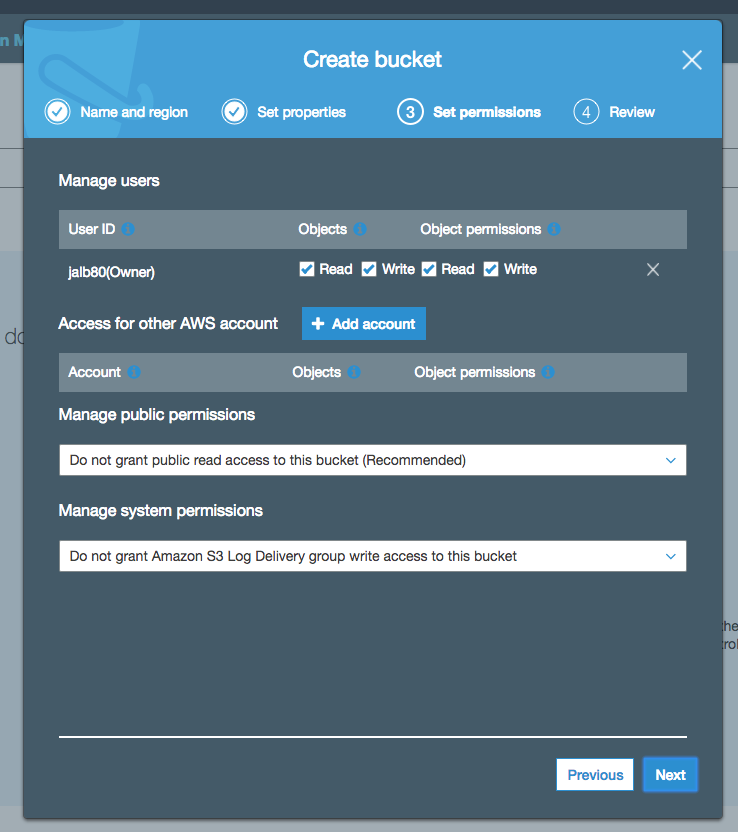
The next step is setting the permissions to access the bucket. As the same as the previous step, we select the default values:
And at the end, we just have to review the bucket details and click on “Create Bucket” button:
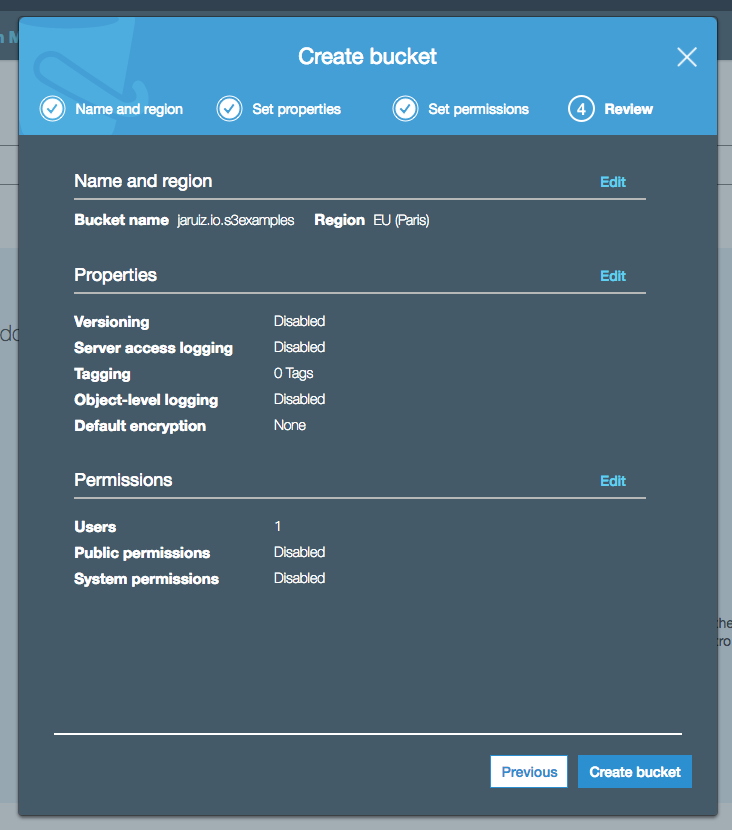
Our bucket is ready:
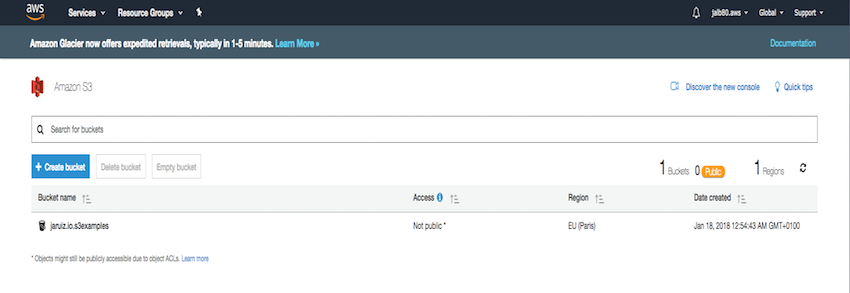
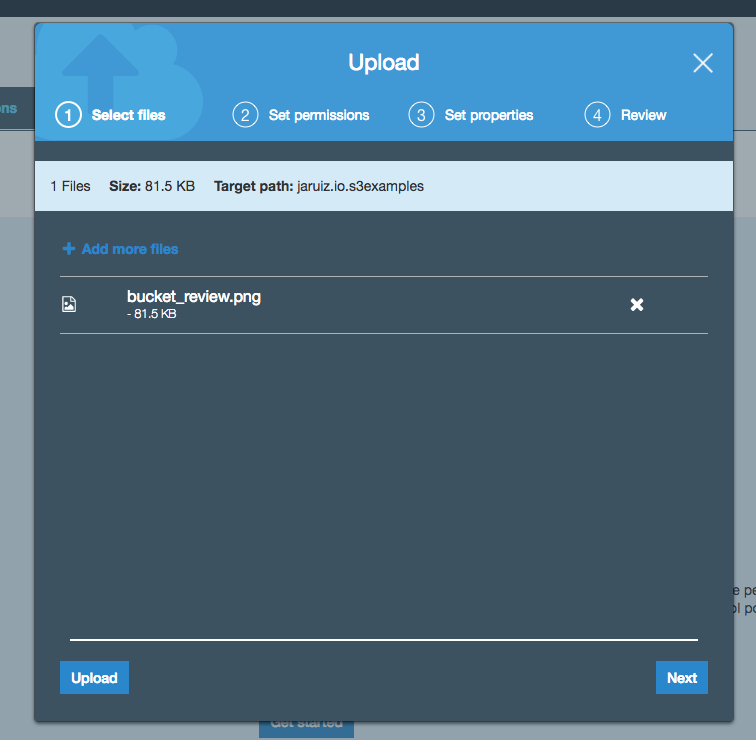
Creating the object
Once we’ve created the bucket, we can upload our first objects. In this example, I’m going to upload an image (bucket_review.png):
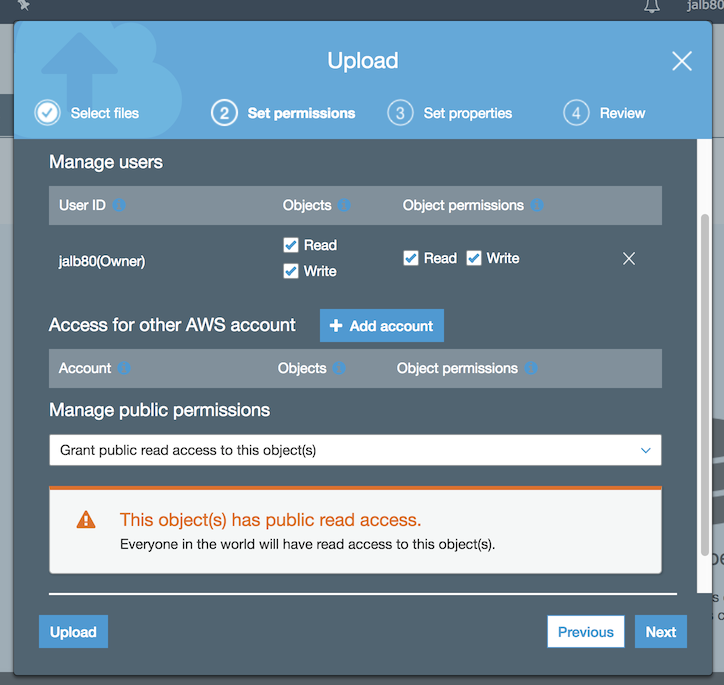
The second step is setting the permissions about the object. The only value that we’re going to change is the section “Manage public permissions” granting public access to the object:
Now, we have to set the object properties. Just like in the previous step, we’re going to use default values (in next posts we talk more about these properties):
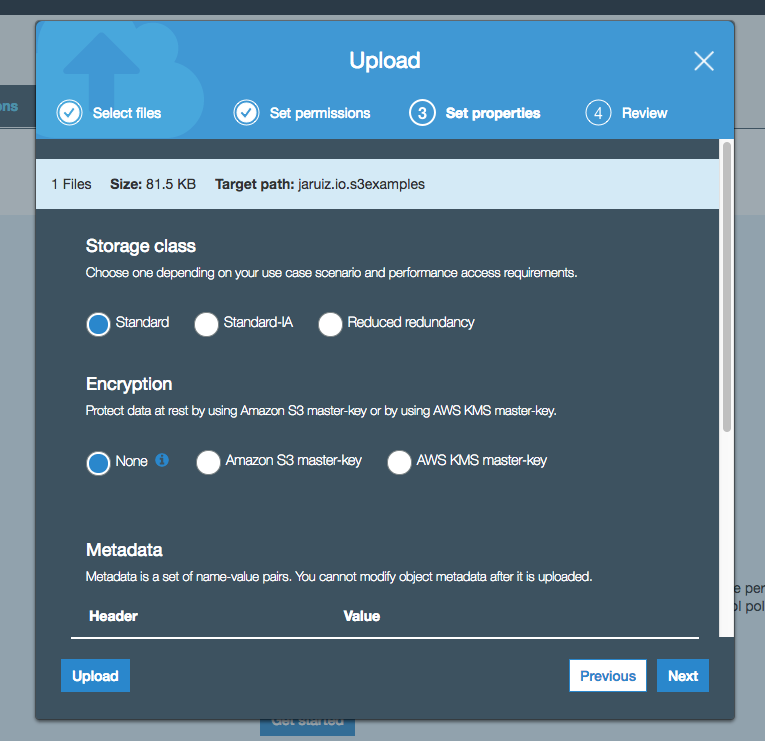
The last step is reviewing and confirming the object upload:
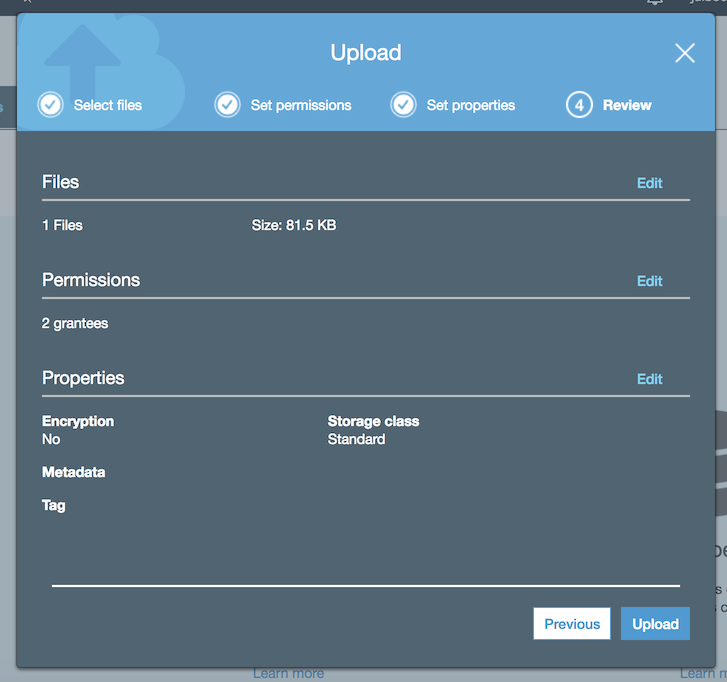
And the object is uploaded in AWS S3:
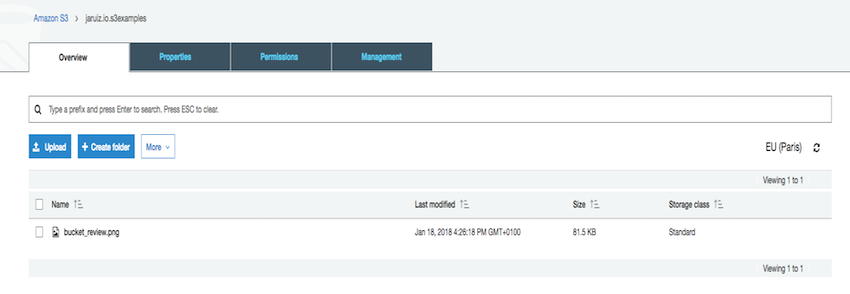
Getting the object
And now, we can get our object by a simple HTTP call.
Remember that the URL has the following format:
http://
.s3.amazonaws.com/
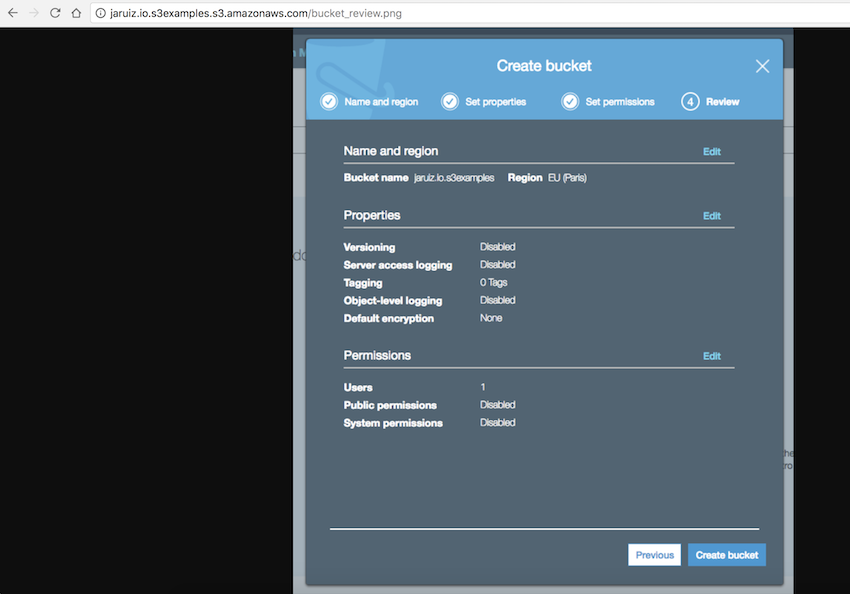
So, our object will be retrieve by the URL:
http://jaruiz.io.s3examples.s3.amazonaws.com/bucket_review.png
I hope you’ve liked this post. In next posts we’ll see advanced S3 features and how to access buckets and objects through the SDK and API.

{kind=link}