This post tries to be post about Kubernetes from the developer point of view, relating Kubernetes concepts with application development. As I always said, the important thing is adquiring knowledge about something and making it yours, In my case, “the JARC way”.
I’m not going to enter in details about how a Kubernetes cluster can be installed or managed but how applications can take advantage of Kubernetes possibillities in order to be scalable and so on.
This post will be a series of several posts where we’re going to go from the concept and theory (but in a “JARC way”) to the real life. I’m not going to enter in details about Kubernetes because the product’s documentation is wonderful and there are already published a lot of books about that. My objective is to try to explain concepts and it applications.
So, I’m going to structure this post this way:
- What is Kubernetes?
- Kubernetes Architecture
- Kubernetes Objects (from 20000 feet)
What is Kubernetes?
Basically, Kubernetes is a platform where containers run. Think about what it means:
- Kubernetes doesn’t provide machines. Kubernetes is not infrastructure. Kubernetes is a platform running over machines, physicals or virtuals. This machines can be located on premise or in cloud.
- Kubernetes doesn’t work with source code, just with binaries. The way you build your images is up to you.
- Kubernetes can execute every kind of containerized workload. Kubernetes is “language/framework” agnostic because it can execute any kind of application while it’s containerized
- Kubernetes schedules containers and it can run several containers from the same image, mananging and distributing requests between them. This ability makes application horizontal scalability possible
Why Kubernetes is so associated with Microservices?
Basically, a Microservice is an independent component, performing a business capability and usually needs some scalability requirements, given by business needs. And, when a microservice scales, it’s necessary to distribute load among the instances.
Other characteristic of microservices is polyglotism, that means, they can be built using any language or framework. If we package our microservices in containers we don’t need a different server to execute them. We just need a container scheduler.
As I said, Kubernetes is a platform where containers run within an specific scalability rules, and working with containers means that every kind of workload can be executed. So, Kubernetes is the perfect tool for microservices.
Kubernetes Architecture
Kubernetes architecture could be summarized in a cluster of nodes where workloads are executed. That cluster is composed by nodes (machines) and some of then adquire the role of workers while the rest adquires the role to coordinate workers and, for instance, decide when and where (worker node) a workload has to be executed.
So, Kubernetes architecture could divide in:
- Worker nodes
- Control plane
Worker nodes
Workloads are executed as containers and it implies executing any kind of workload and to do that, it’s necessary to have a set of machines.
Kubernetes is not associated to a specific infrastructure technology. It just needs a set of machines to create its cluster and manage containers on them. It’s possible to install Kubernetes on premise or in cloud.
These nodes are commonly known as workers or workers nodes.
Kubernetes can work with only a node but in the real world, multiple nodes are necessary. The number of nodes depends on, for instance, the number of environments (dev, pre, pro…) or the compute needs that applications, running in the cluster, require.
Control Plane
For sure, you’re wondering how Kubernetes knows in which Pod has to run a container or how nodes are managed. Those kind of tasks are managed by “the control plane”. The Control Plane has the following components:
- An API to expose Kubernetes features outside the cluster. This is called kube-apiserver
- A component to store Kubernetes data. This piece is etcd and stores Kubernetes data in a key-value way
- A component to decide in which node run new containers. This component is the scheduler, called kube-scheduler
- A component to control Kubernetes processes like checking if nodes are up and running or if the desired number of the containers associated to an image are launched. This component is kube-controller-manager
- If the cluster is deployed on a Cloud provider, a component to interact with this cloud provider is necessary. This component is cloud-controller-manager
Components from Control Plane aren’t deployed in workers nodes. They are deployed in other king of nodes called master nodes
Control Plane needs some components in every node in order to manage the cluster. These components are:
- A component checking that containers are running, called kubelet
- A component to extend the Kubernetes API to each node and manage network, called kube-proxy
- A container runtime
Summarizing, working with Kubernetes means that your application must be containerized and this containers will run in some node of the cluster.
I like this image from the Kubernetes main page to show the architecture:

Kubernetes Objects
Kubernetes works in a declarative way, that means that the desired state of the system is declared and Kubernetes will try to provide this state. The state could be about containers, like “X containers running of service A”, “Y containers running of service B” or “a container executing every day at 10 o’clock “ but it also about how containers and other elements work together, for instance: “container A could not call to container B”, “container B can’t not consumer more CPU than X”, “container C stores its data in that space” or “container D has to expose outside the cluster”.
An object in Kubernetes is represented by a YAML file. This file shows how the desired state.
Till now, I’ve not talking about Pods, Services, Volumes or Deployments because I think it was better understand the concept of Kubernetes. From now, I’ll introduce those objects from the use cases
Kubernetes objects from 20000 feet
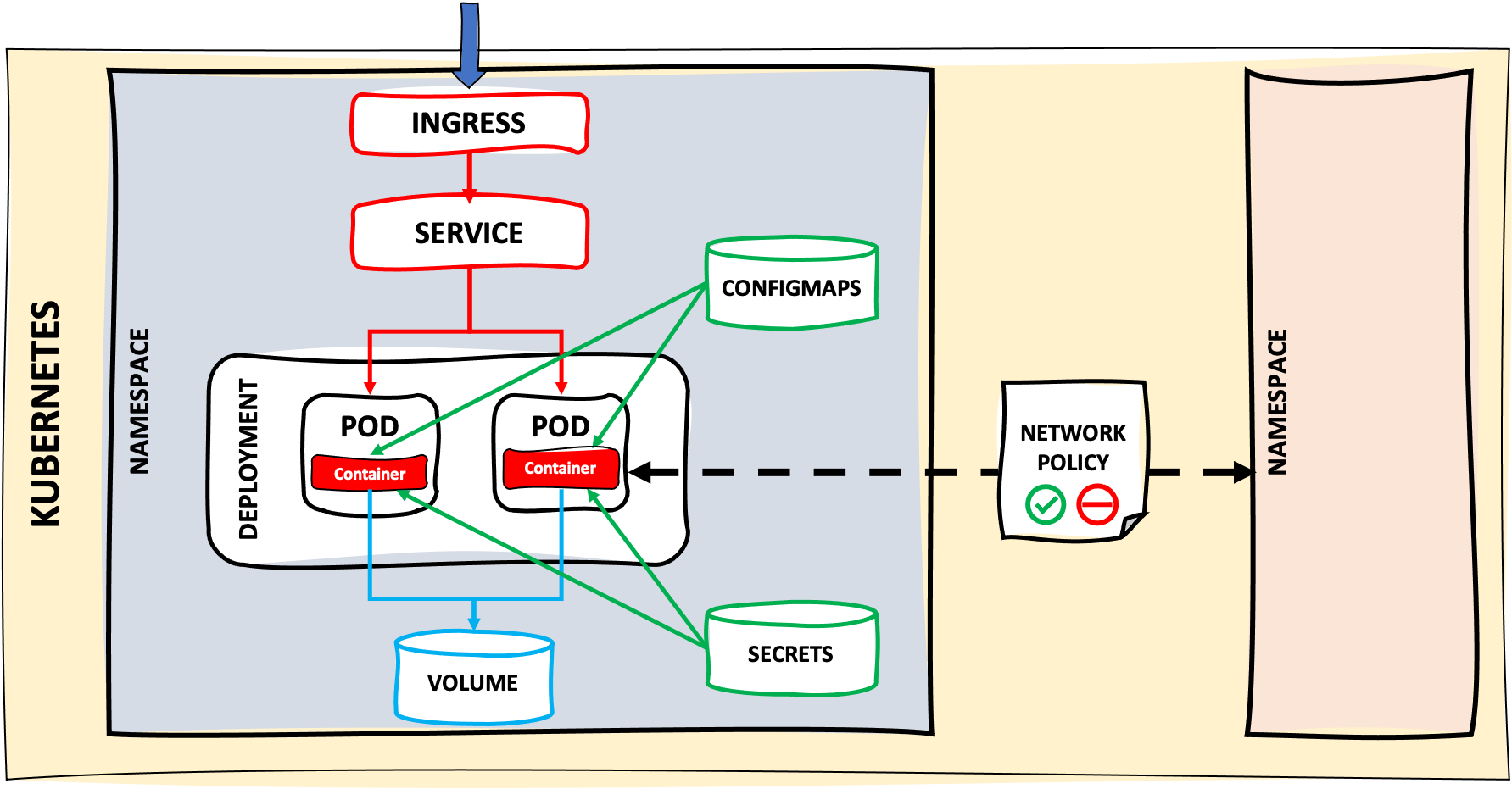
Now, I’m going to identify the main Kubernetes objects that take part from a developer point of view:
- Our container is executed within a Pod. A Pod contains at least one container but it can be more than one (we’ll see it later)
- Our container needs some configuration or variables. This information is injected by ConfigMaps and Secrets
- Information stored in containers or Pods is ephemeral, that means, that when the container or Pod terminates, information is also removed. If we want to persist this information, we’ll need Volumes and Persistent Volumes that we’ll associate to the Pod.
- If our application needs to scale up or down, depending on load, memory, CPU… and creating or removing Pods as necessary or selecting a deploy strategy, we’ll use a Deployment object
- As Pods usually are “ephemeral” elements and maybe we need to scale up or down, adding or removing Pods, requests to these Pods need to be distributed and balanced. Kubernetes uses a Service to achieve it
- Maybe, we need to expose our application to the outside world. To do that, we’ll use an Ingress
- When our ecosystem of services is relatively big, we’ll need to organize environments and domains by Namespaces
- Sometimes we’ll need to add some restrictions regarding to Pods interactions in order to limitate some comunications between Pods or allowing just certains ports or even not allowing communication between elements in different namespaces. Kubernetes provides Network Policies to manage this kind of behaviours.
There are other Kubernetes objects but I think these are the most important from a developer point of view. This picture summarize the points below:
Basic structure of a Kubernetes Object
Every Kubernetes object is defined by four parts:
- API Version: version of the Kubernetes API that supports that object
- Kind: which kind of object we want to manage: Pod, Service, Deployments…,etc
- Metadata: name, labels, annotations,…,etc
- Spec: desired state of the object
The physical representation of these four parts is made by a file, YAML or JSON. As Kubernetes is “state oriented”, every object has its YAML or JSON representation.
For instante, this is the YAML associated to a Pod:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
labels:
post: kubernetes
spec:
containers:
- name: nginx
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
Kubectl
Kubectl is the command line tool used to manage a Kubernetes cluster. This tool, behind the scenes, performs HTTP request agains Kubernetes API.
Kubectl sintaxis is normalized. The pattern is:
kubectl <command> <kubernetes object group> <aditional info>
Where:
- command: get, edit, delete, describe, logs, exec….
- kubernetes object group: pods, services, deployments, configmaps, etc…
Aditional info depends on the command executed. For instance, if we want to get the detail of an specific pod, we’ll execute:
kubectl describe pods <pod name>
I’m not going to explain in detail every command because you can find a really good cheatsheet in the official product’s page but the most common commands could be:
-
You need information about components in any namespace:
-
Get pods in all the namespaces
kubectl get pods --all-namespaces -
Get all objects within a namespace
kubectl get all --namespace=<namespace>
-
-
Deploying components:
-
Apply a YAML file or a set of YAML files:
kubectl apply -f <YAML file / folder containing YAML files>
-
-
Checking is everything’s ok:
-
Get information about pods in a concrete namespace
kubectl get pods --namespace=<namespace> -
Get pod’s detail
kubectl describe pods <name> --namespace=<namespace> -
Delete a pod (default namespace):
kubectl delete pods <pod name>
-
Bonus track
As I said, kubectl executes calls to Kubernetes API. If you want to check how these calls are you can add a parameter to shows “debug” information. For instance, if I execute the command to get pods in the namespace “jenkins” but add the flag “–v=7”:
kubectl get pods --namespace=jenkins --v=7
I see the HTTP request:
I0128 10:53:06.370206 3279 loader.go:375] Config loaded from file: /Users/jaruiz/.kube/config
I0128 10:53:06.394297 3279 round_trippers.go:420] GET https://0.0.0.0:56093/api/v1/namespaces/jenkins/pods?limit=500
I0128 10:53:06.394320 3279 round_trippers.go:427] Request Headers:
I0128 10:53:06.394326 3279 round_trippers.go:431] Accept: application/json;as=Table;v=v1;g=meta.k8s.io,application/json;as=Table;v=v1beta1;g=meta.k8s.io,application/json
I0128 10:53:06.394336 3279 round_trippers.go:431] User-Agent: kubectl/v1.19.3 (darwin/amd64) kubernetes/1e11e4a
I0128 10:53:06.410273 3279 round_trippers.go:446] Response Status: 200 OK in 15 milliseconds
NAME READY STATUS RESTARTS AGE
jenkins-7498d554cc-smsrf 1/1 Running 1 34h
How can I have “my local cluster”?
There are some possibilities to create a local Kubernetes cluster to make some PoCs or simply having a quick start.
I can talk about these alternatives that I’ve used without entering into details:
- Minikube: this is the most popular one and I’ve been using it for several years. It’s easy to install and manage. The main page is here
- K3D: this is the one I’ve using currently and, for now, the impressions are really good. The main page is here.
There are other local alternatives like Kind
And if you don’t want to have a local cluster, you can use any Cloud solution like Okteto
This is the first post on “Kubernetes - The JARC way”. In the next posts, we’ll see in detail the most important Kubernetes objects associated to development aspects instead of learning each one without more context….

){kind=link}